Why schema design is so important
Airfold is powered by the open-source analytics engine ClickHouse, known for its exceptional performance in aggregating large volumes of data at speed. ClickHouse offers a range of advanced features not typically found in other platforms—features that can significantly impact performance when used effectively. One of the most important ways to take advantage of these capabilities is through thoughtful table schema design.If you have questions about optimizing your schema or improving query performance, reach out to your assigned Solutions Engineer—they’ll be happy to provide guidance tailored to your project.
Data Types
ClickHouse supports all the familiar data types you’d expect—likeString, Int, and DateTime — but it also includes several powerful, ClickHouse-specific types designed for performance and flexibility. These include LowCardinality for efficient storage of repetitive string values, and JSON for working with semi-structured data. Choosing the right data type can have a big impact on query speed and storage efficiency.
Materialized Incremental Views are another powerful feature of ClickHouse. To take full advantage of them, you’ll need to use a special data type called AggregateFunction, which allows ClickHouse to store pre-aggregated values for blazing-fast query performance. See the reference page to learn more about data types.
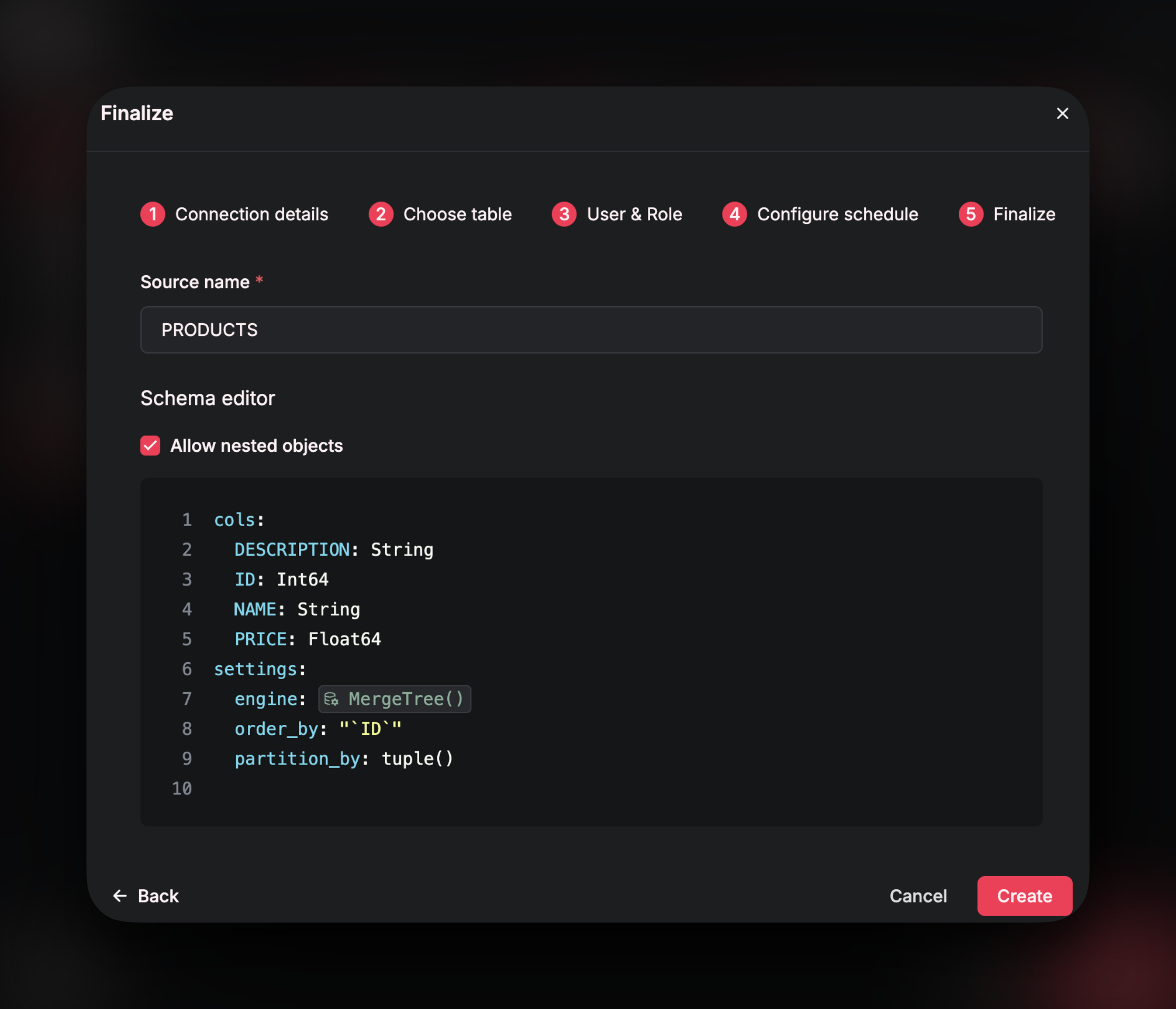
Engine
In ClickHouse, you can specify a Table Engine that determines several key behaviors of the table, such as how data is stored on disk, how it is indexed, and potentially how data can be deduplicated. Some of the common engine types you will use in your Airfold project:MergeTree is the most frequently used table that merges table parts in the background, ReplicatingMergeTree deduplicate rows (based on a version column) ensuring your query includes the most up to date data, and AggregatingMergeTree for Materialized Incremental Views that aggregate data on ingestion.
Choosing the right engine is critical for optimizing performance and ensuring the table aligns with your use case, whether it’s high-speed inserts, deduplication, or aggregations.
Check out our reference page to learn more about ClickHouse Engines.
Primary Key/Order By
In ClickHouse, thePRIMARY KEY and ORDER BY table settings are essential to how your data is organized and queried. Unlike traditional databases, where a primary key enforces uniqueness, in ClickHouse the Primary Key is used purely for indexing. It defines the sorting order for the data and determines how ClickHouse organizes parts on disk and builds sparse indexes for efficient filtering.
Choosing a good ORDER BY column is arguably the single most impactful decision you can make for improving query performance. Ideally, it should be a column that is frequently used in filters—this allows ClickHouse to skip over large portions of data during query execution, significantly reducing scan time.
For example, a table with a schema like this:
Partition By
Thepartition_by clause in ClickHouse controls how your data is physically split across directories on disk. While it doesn’t directly improve query performance like order_by does, it plays a big role in data management—especially for controlling data retention, optimizing merges, and speeding up certain types of bulk deletes. A good partitioning strategy can reduce storage overhead and make your table easier to maintain over time.
A common choice is to partition by date, although it is recommended to partition data at the month level.
Optimizing your schema from the start ensures your tables are fast, efficient, and aligned with your workload. ClickHouse (and by extension, Airfold) does not allow you to change core settings like engine, order_by, or partition_by after a table is created. Making changes later typically means dropping the table, recreating it with the new schema, and backfilling all your data. It’s worth getting it right the first time!