What Are Pipes?
A Pipe is a data processing workflow that takes your data, processes it through one or more steps, and returns a meaningful output. Pipes are designed to be:- Flexible – Transform, and aggregate data with ease
- Powerful – Build complex analytics workflows
- Modular – Break down logic into manageable, testable units
Nodes: The Building Blocks
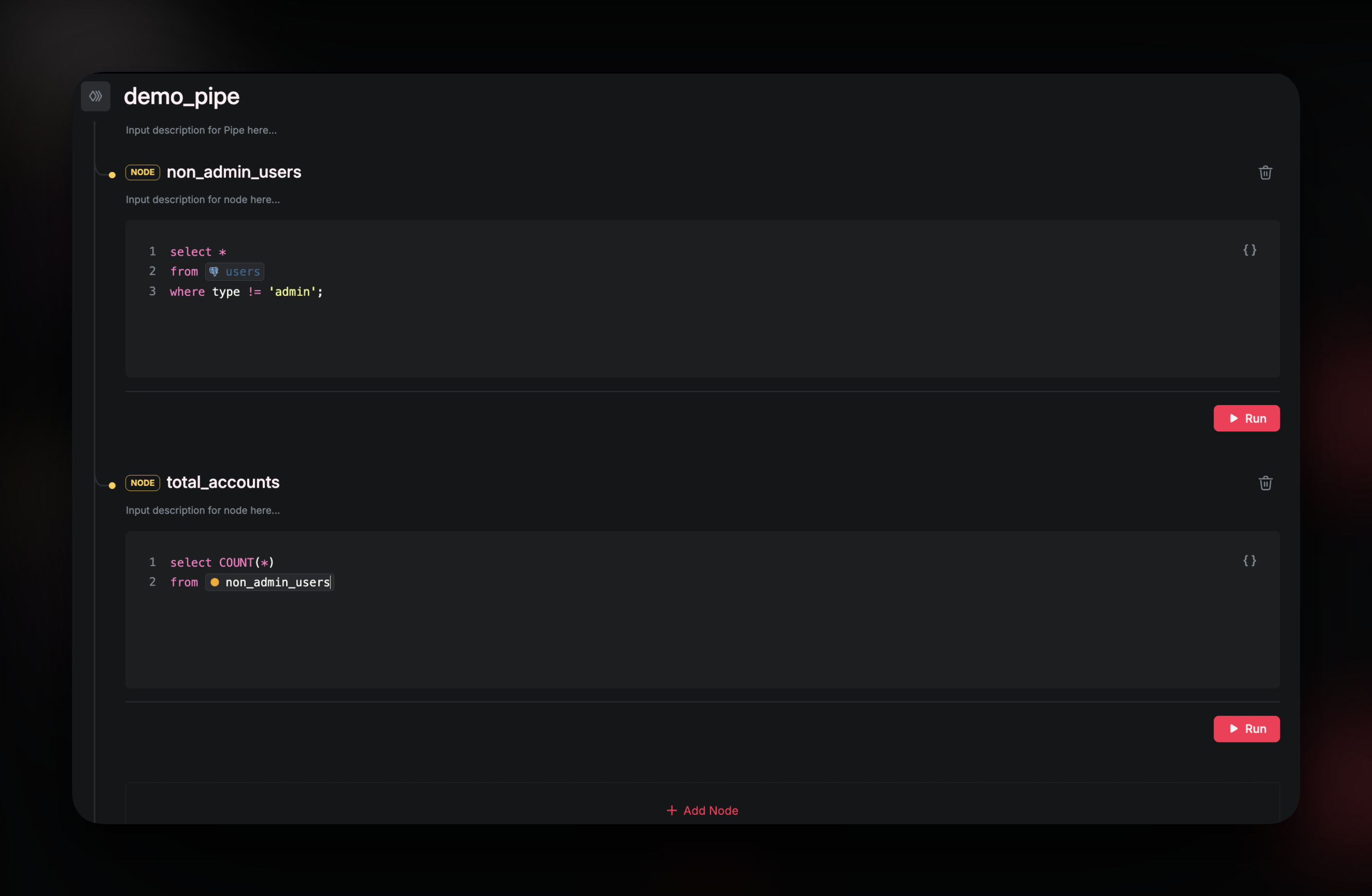 Nodes are the fundamental units within a Pipe. Each Node contains a single SELECT query representing a specific step in the data processing workflow.
Nodes are:
Nodes are the fundamental units within a Pipe. Each Node contains a single SELECT query representing a specific step in the data processing workflow.
Nodes are:
- Standalone or Connected: Nodes can operate independently or as part of a chain
- Like CTEs, but Better: They resemble Common Table Expressions, but can be executed and debugged individually
- Composable: Output from one Node can be referenced by another downstream Node
- Airfold Sources
- Previous nodes
- Other Published Pipes
Types of Pipes
Pipes can be created and managed using either the UI or the CLI. This page outlines how to work with each type of Pipe through both interfaces.Draft Pipes
Draft pipes are temporary pipelines used for development and testing:- They do not persist results
- Cannot be referenced by other pipes using FROM
- Serve as the foundation for published or materialized pipes
UI
Navigate to “Pipes” on the left menu column, and click on ”+”: Enter a name for this query, then press “Create”.
Here, you have a node where you can enter a single SQL
Enter a name for this query, then press “Create”.
Here, you have a node where you can enter a single SQL SELECT statement to query your tables directly.
These SQL statements can interact with your sources/tables in the same way as standard SQL tables.
For example, to get the top referrers as in our quickstart example we can run the following command.
CLI
Pipes are created and managed through YAML files. To create a draft pipe by using the CLI, create a YAML file as below:draft_pipe.yaml
The name of the pipe. Optional
A brief description of the pipe’s purpose or functionality. Optional
The sequence of nodes within the pipe. Each node represents a stage in data processing.
Published Pipes
Published pipes create API endpoints that expose query results in multiple formats like JSON and CSV- Accessible via endpoints and usable in other pipes
- Supports parameterized SQL using Jinja2 templates
- Results are computed on read
UI
Click on “Save” to save the SQL in your pipe, then click “Publish” to publish it as an endpoint: That’s it, your draft pipe just became a publihsed pipe, you can go to view endpoints and use any of the Javascript, Python or curl command to ping the endpoint.
CLI
This creates an API endpoint that serves the result of your pipe, the result is accessible in JSON, NDJSON, CSV, and Parquet formats. To publish a draft pipe, assign an endpoint name to thepublish field.
Published pipes can parameterize their SQL using Jinja2 via the params field.
Unlike draft pipes, published pipes can be accessed (via FROM) by other pipes.
published_pipe.yaml
The name of the pipe. Optional
A brief description of the pipe’s purpose or functionality. Optional
The sequence of nodes within the pipe. Each node represents a stage in data processing.
The endpoint name where the results are published, turning the pipe into a published pipe. This option cannot be used with to. Optional
A list of parameters for parameterizing node SQL queries through Jinja2 templating e.g.
{{ param }}. These parameters are passed via the API and can be used to dynamically alter the pipe’s behavior. OptionalMaterialized Pipes
Materialized pipes transform and store results in a target source:- Results are appended to a designated source for faster access
- Designed for incremental updates
- Results persist, unlike published pipes
Incremental Materialization
Airfold’s materialized pipes support incremental data transformation by automatically ingesting new data as it arrives. This model ensures your pipeline only processes fresh data ideal for time-series logs, user activity streams, or continuously growing datasets.- Enables near-real-time aggregations and rollups
Note: Incremental Materialized Pipes in Airfold are designed to process only newly arriving data. If historical data already exists in your target tables, you must perform a backfill to ensure completeness.Backfilling refers to the process of reprocessing or re-ingesting historical data so that it is captured by the incremental materialization logic. Without this step, pre-existing data will be excluded from downstream views and analytics.To learn how to perform a backfill, see Backfill Your Data.
Refreshable Materialization
Recomputes transformations across the entire dataset- Can be scheduled refresh interval
- Replace existing materialized data with updated results
- Are suited for dimension tables, slowly changing datasets, or recalculated KPIs